GPU Parallel Computing: A Deep Dive into Modern Graphics Processing
An exploration of how GPUs achieve parallel computing through their unique architecture, comparing it with CPU processing and explaining the fundamental differences between serial and parallel computation methods.
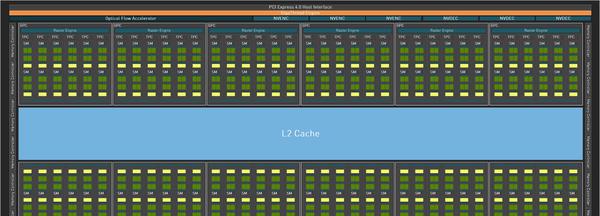
Modern GPU architecture represents one of computing’s most significant achievements in parallel processing. While CPUs excel at sequential tasks with their powerful but limited number of cores, GPUs harness thousands of simpler cores to perform massive parallel computations simultaneously.
The fundamental difference between CPU and GPU processing can be understood through a simple analogy. Imagine a CPU as a master chef in a kitchen - highly skilled and capable of handling complex cooking tasks, but limited by having only two hands. In contrast, a GPU is like a large fast-food restaurant kitchen with hundreds of cooks, each performing simple, specific tasks simultaneously. While individual cooks might be less skilled, their combined effort produces results much faster than a single master chef.
The GPU’s parallel processing capability is built on several key architectural features:
CUDA cores form the foundation of NVIDIA’s parallel computing platform. A modern GPU like the NVIDIA RTX 4090 contains over 16,000 CUDA cores, each capable of handling basic mathematical operations simultaneously. These cores are organized into Streaming Multiprocessors (SMs), which manage and schedule the workload efficiently.
Memory architecture plays a crucial role in GPU parallel processing. Unlike CPUs, which access memory sequentially, GPUs utilize wide memory buses and sophisticated caching mechanisms to feed data to thousands of cores simultaneously. This is particularly important in applications like machine learning, where massive amounts of data need to be processed concurrently.
Task scheduling in GPUs operates on the SIMD (Single Instruction, Multiple Data) principle. When a GPU receives a computational task, it breaks it down into thousands of smaller tasks that can be processed independently. The GPU’s hardware scheduler then distributes these tasks across available CUDA cores, ensuring optimal utilization of resources.
The efficiency of GPU parallel processing makes it particularly valuable in several key applications:
Graphics rendering and image processing benefit from the GPU’s ability to manipulate millions of pixels simultaneously. Each pixel transformation can be handled by a separate core, allowing for real-time processing of complex visual effects.
Scientific computing, particularly in fields like climate modeling and molecular dynamics, leverages GPU parallel processing to perform millions of calculations simultaneously. These applications often involve matrix operations that can be naturally parallelized across thousands of cores.
Machine learning and artificial intelligence training have been revolutionized by GPU computing. The parallel nature of neural network calculations aligns perfectly with GPU architecture, enabling the processing of vast datasets at unprecedented speeds.
The evolution of GPU architecture continues to push the boundaries of parallel computing. Modern GPUs integrate specialized cores for ray tracing, tensor operations, and other advanced computations, while maintaining their fundamental strength in parallel processing. This combination of specialized hardware and massive parallelism enables GPUs to tackle increasingly complex computational challenges across diverse fields of application.